Upload Files with Hasura and Hasura Storage
13 August 2022


Hasura does an excellent job providing an easy way to manage data for your application. But what about uploading and downloading files?
This is the problem. Hasura does not have a native way of uploading and downloading files. It's not even possible to use a remote schema to upload files via Hasura (open issue since 2019).
Instead, files have to be managed alongside Hasura.
At Nhost, we've open sourced Hasura Storage to solve this problem.
Hasura Storage is built on top of Hasura and S3 to make it easy to upload and download files along side Hasura.
The concept of Hasura Storage is simple:
- Files are uploaded and downloaded via Hasura Storage
- Files are stored in S3
- File metadata is stored in the database (via Hasura)
- Permissions are managed by Hasura
Let's expand each of the topics:
Files are uploaded and downloaded via Hasura Storage
Because it's not possible to use GraphQL and Hasura to upload and download files, we need to do that alongside Hasura.
Because of this limitation, Hasura Storage is a separate service and is deployed alongside Hasura. Hasura Storage is the entry point for users to upload and download files.
Files are stored in S3
Since storing files in the database is inefficient, files are stored in S3. This can be AWS S3, or any other S3 compatible service like Minio which is open source.
File metadata is stored in the database (via Hasura)
When a user uploads a file two things happen:
- Hasura Storage stores the file in S3
- Hasura stores the file metadata in the database
The reason the file metadata is stored in the database has a few benefits:
- We can use Hasura's permission system to manage permission rules for a file (see next section).
- We can use GraphQL to query file metadata and show it in our application.
- We can create foreign keys and GraphQL relationships between files and other tables in our database.
The file metadata is stored in storage.files table and includes:
id- Unique identifier for the filecreated_at- When the file was uploadedupdated_at- When the file was last updatedbucket_id- The ID of the bucket the file is stored inname- The name of the filesize- The size of the file in bytesmime_type- The MIME type of the fileetag- The ETag of the fileis_uploaded- Whether the file has been completly uploaded or notuploaded_by_user_id- The ID of the user who uploaded the file. This column is deprecated and will be removed in the future.
Permissions are managed by Hasura
We use Hasura's permission system to manage who can upload and download files. We're able to do this because the file metadata is stored in the storage.files table and that table is tracked by Hasura.
This way, it's easy to allow users to upload and download files based on things like application data or file metadata.
Example: Users are only allowed to download files that belong to companies the user also belongs to:
For this select permission, we're using the relationships between tables. From storage.files we can go to public.company_files to public.companies to public.company_members to make sure the user belongs to the same company the files belongs to.
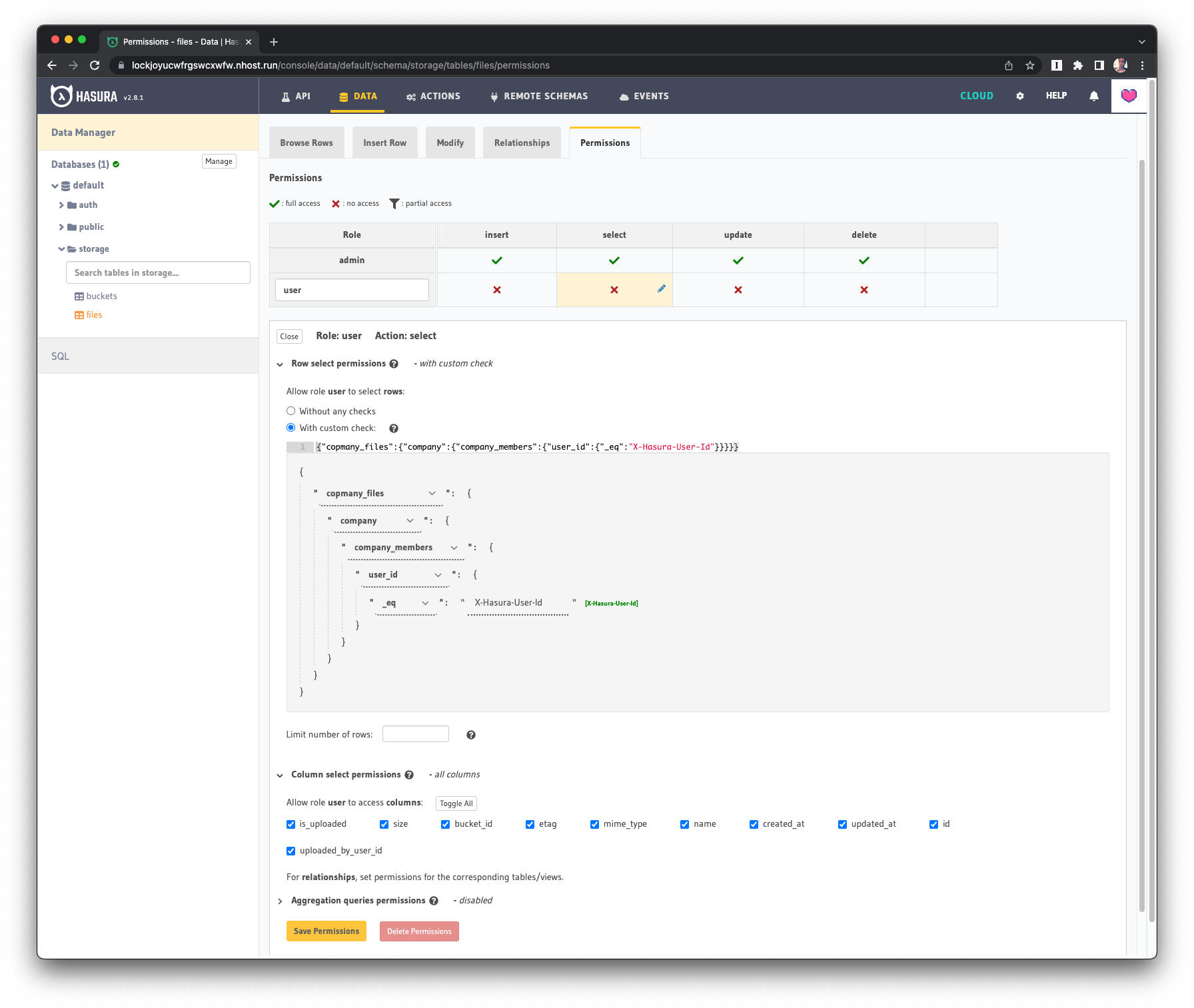 Select Permission example in Hasura for Hasura Storage: Company
Select Permission example in Hasura for Hasura Storage: Company
Example: Users are only allowed to upload PDFs:
For this insert permission, we're making sure the file's MIME type is of type application/pdf.
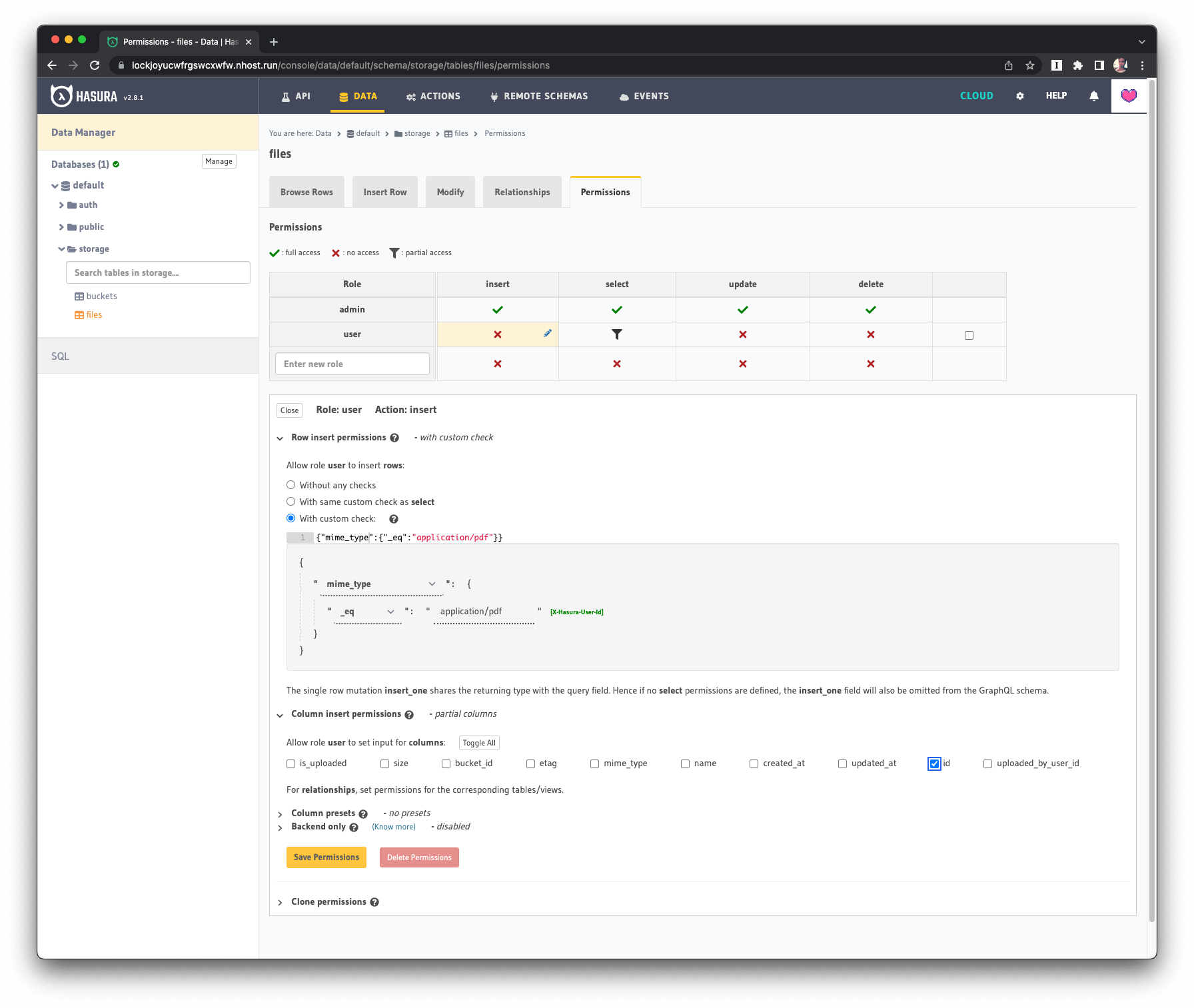 Insert Permission example in Hasura for Hasura Storage: PDFs only
Insert Permission example in Hasura for Hasura Storage: PDFs only
Example: Users are only allowed to upload files with a max file size of 5 MB:
For this insert permission, we're making sure the file size is less than (_lt) 5,000,000 bytes (5MB).
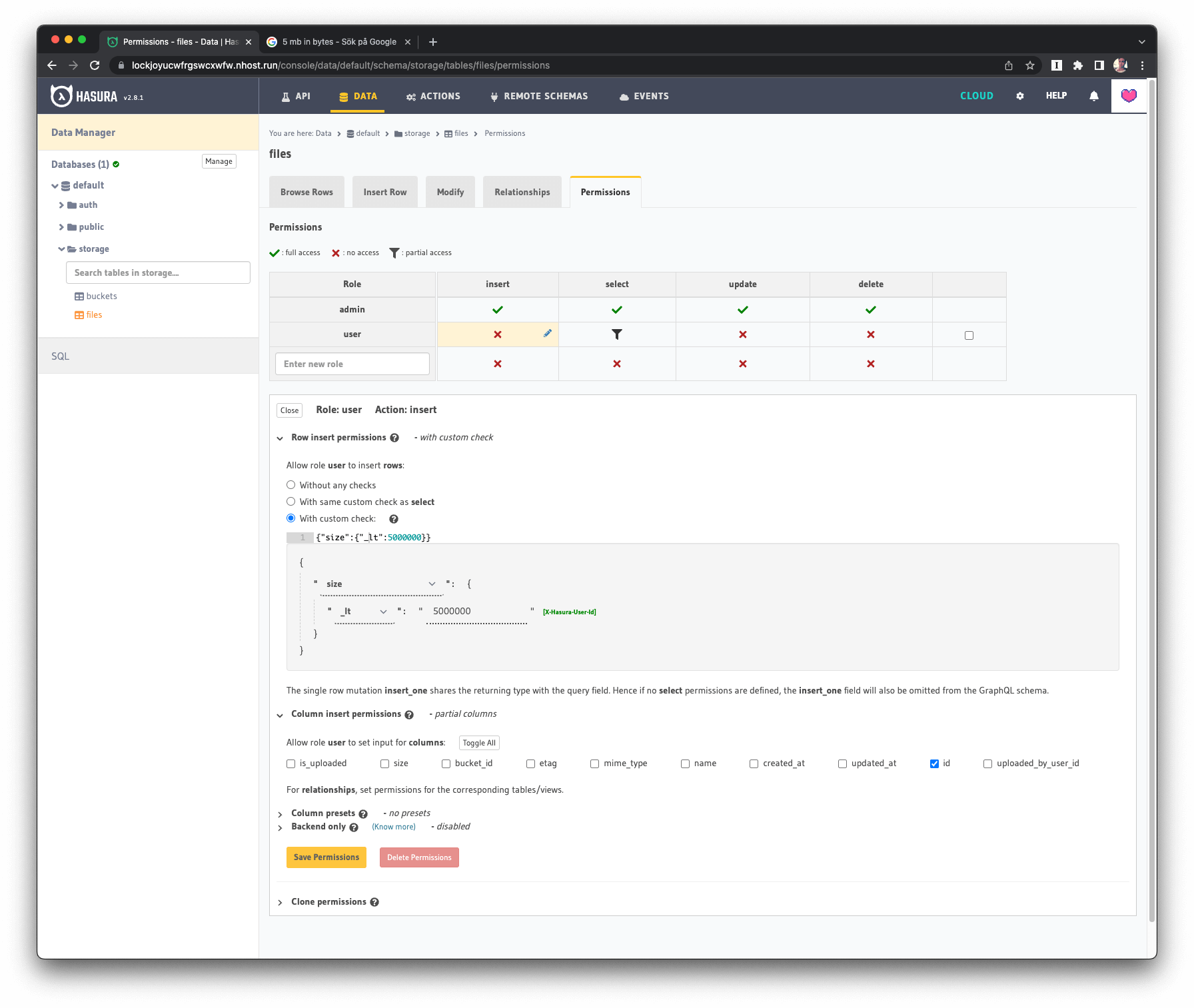 Insert Permission example in Hasura for Hasura Storage: Max 5 MB
Insert Permission example in Hasura for Hasura Storage: Max 5 MB
Technical Overview
From a technical perspective, there are two main concepts Hasura Storage handles: uploading and downloading. Let's look at how requests flow between the user, Hasura Storage, Hasura's GraphQL API, and S3.
Upload
This is how uploading a file works:
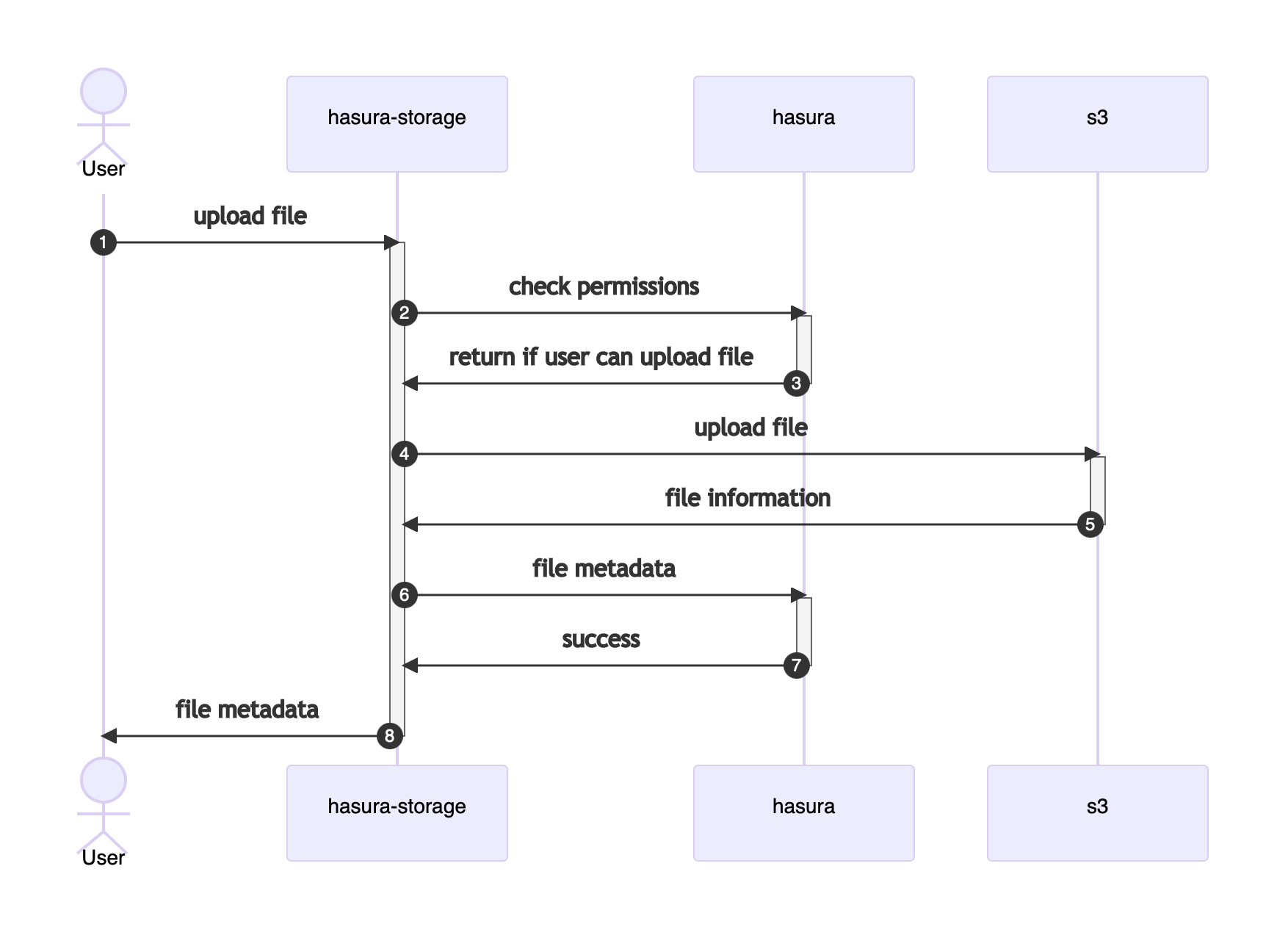 Upload a file
Upload a file
Download
This is how downloading a file works:
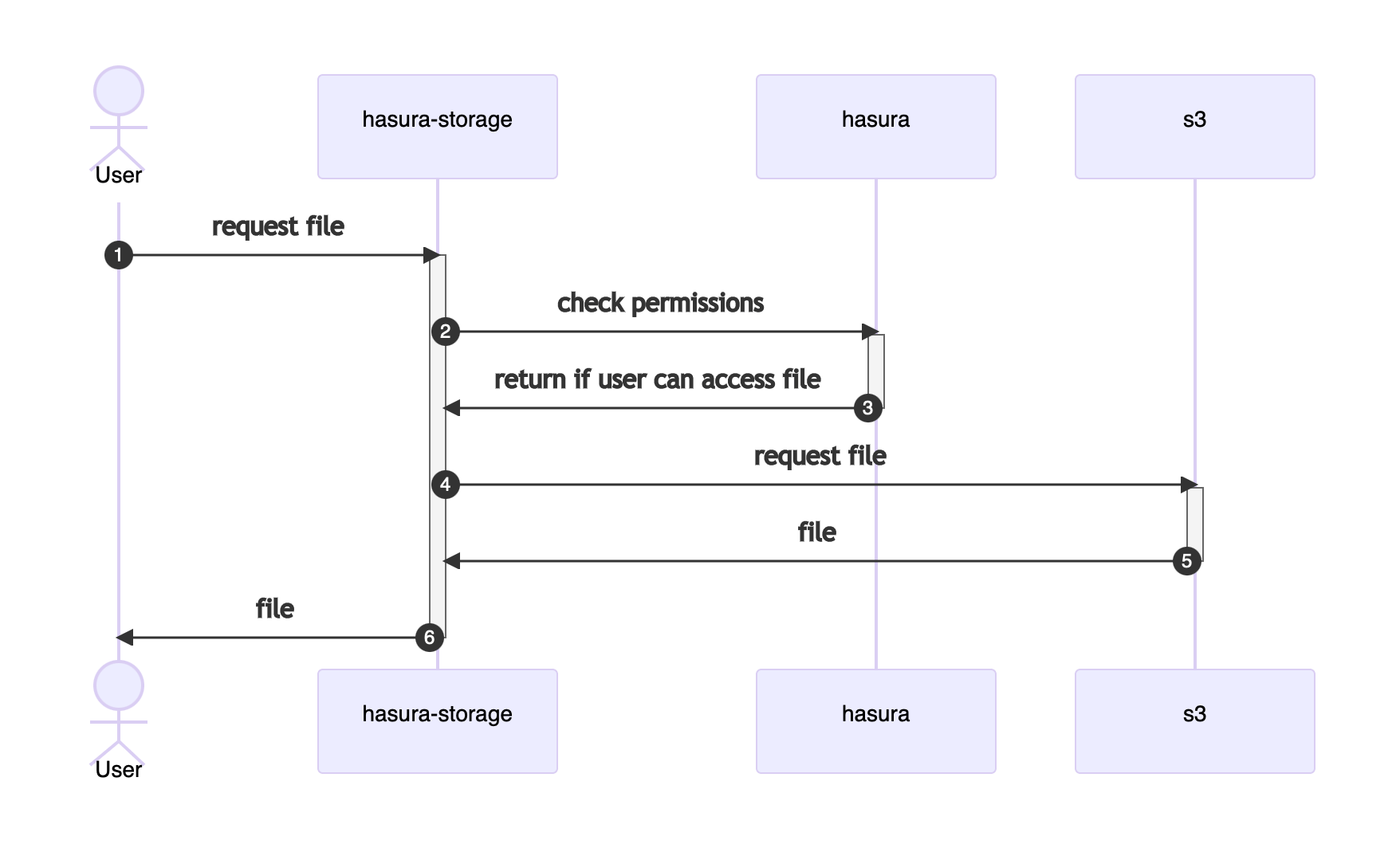 Download a file
Download a file
History
Hasura Storage is the result of three iterations of storage service for Hasura.
First, we open sourced Hasura Backend Plus (first iteration) which included both authentication and storage.
Having authentication and storage in a single service wasn't the best idea so we decided to split the service into two separate services. Hasura Auth and Hasura Storage.
Having the services separated made it easier to reason, maintain and scale each service individually.
Hasura Storage was first re-written in Node.js (second iteration) with an updated way of managing file permissions via Hasura. Soon after, the Node.js version was ported to Go (third iteration) for performance reasons.
CDN
If we're using Nhost to host Hasura Storage you also get a CDN for Storage out of the box. You can read the CDN announcement here.
PS. Star us on GitHub
Support our open source work:
Thank you.
Share this post