AI Superpowers with Nhost Postgres & Auto-Embeddings
18 December 2023


Welcome to Nhost's AI Week!
This week we're releasing our AI toolkit, a new set of tools to simplify and enhance the development of AI-driven applications.
Between today and Thursday we will unveil new AI capabilities through blog posts, while Friday will be dedicated to releasing all features alongside a new AI service, graphite, for all of you to enjoy.
As we strive to integrate cutting-edge AI capabilities into your applications and businesses, we are excited to unveil two new features today: Nhost Postgres as a Vector Database & Auto-Embeddings.
Nhost Postgres, your Vector Database
We're in the midst of the AI revolution and efficient data processing has become crucial for applications that involve large language models and semantic search.
Due to their efficiency, vector databases have become a cornerstone of the AI revolution. A Vector Database is a specialized type of database that can store high-dimensional vectors, and allow AI applications to efficiently search through data and retrieve the closest matching database records.
You can now use Nhost Postgres as a vector database to store embeddings and unlock a whole new set of applications around:
- Semantic Search
- Data Clustering
- Text Classification
- Product Recommendation
pgvector
Nhost leverages pgvector, an extension for Postgres designed to support efficient storage and search on high-dimensional vectors required by applications searching through complex entities like images, documents, text, or videos.
Key features of pgvector include:
- Vector Indexing to allow for the creation of indexes on vector columns, which can significantly speed up nearest neighbor searches.
- Support for High-Dimensional Data.
- Various Distance Metrics usually used in the vector space (L2 distance, cosine similarity, etc).
- Ease of use, specially for those already familiar with PostgreSQL.
You can start using pgvector today, just make sure you are running on the latest version of Nhost Postgres and install it with:
_10CREATE EXTENSION IF NOT EXISTS vector;
Simplifying Embeddings
Auto-Embeddings, leveraging pgvector, is our secret sauce that makes creating and updating embeddings as easy and straightforward as it can be.
With just a few configurations, our AI service, graphite, is capable of ensuring that your embeddings are always up-to-date and stored alongside your data.
Auto-Embeddings in practice
Consider a database of movies with a table movies and a column embeddings of type vector. All we have to do is tell our AI overlord how to fetch and update outdated embeddings:
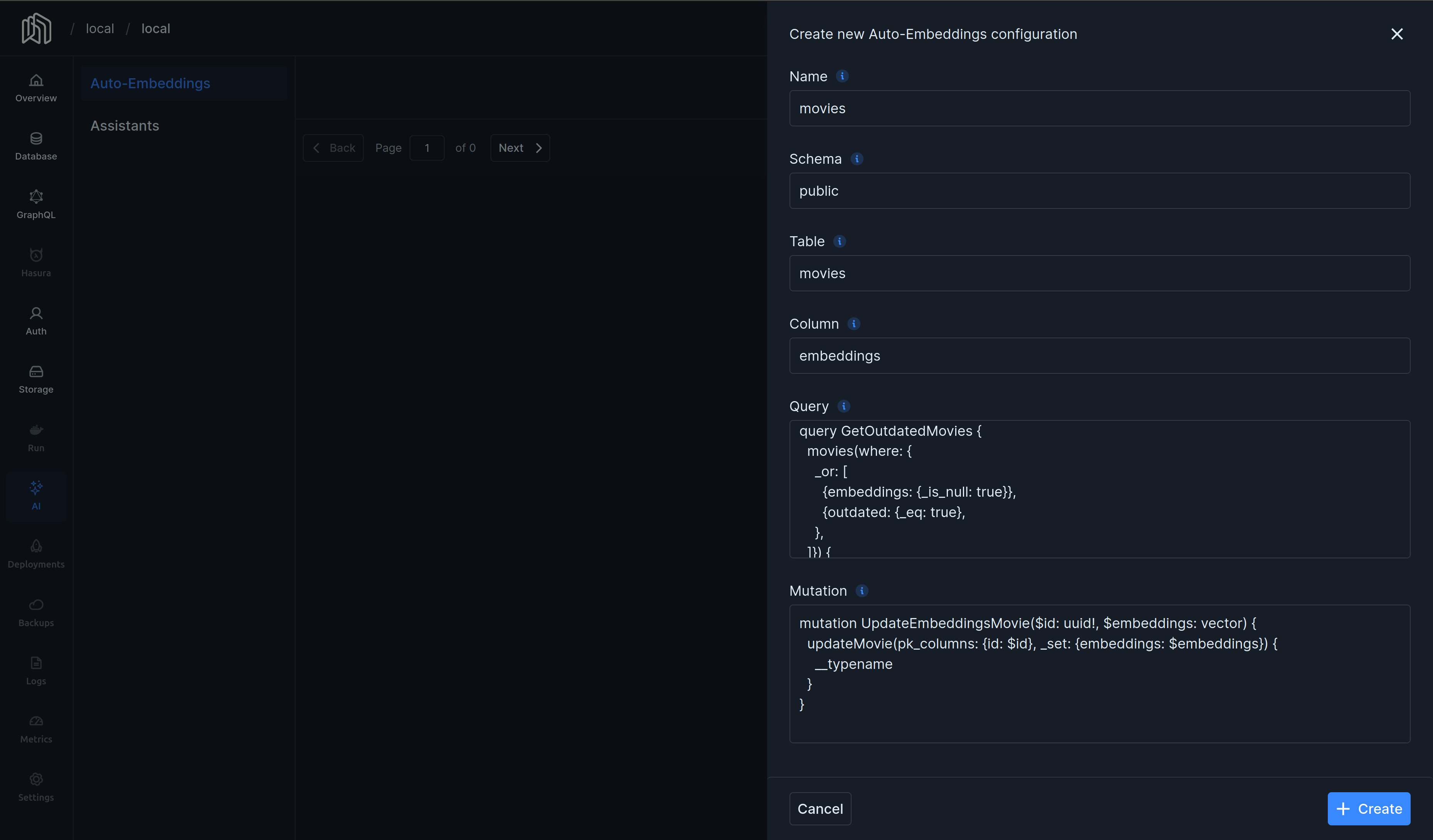 Configuring Auto-Embeddings
Configuring Auto-Embeddings
A query and a mutation is all we need!
All embeddings will be generated and kept up-to-date, without us having to do anything. It's that easy.
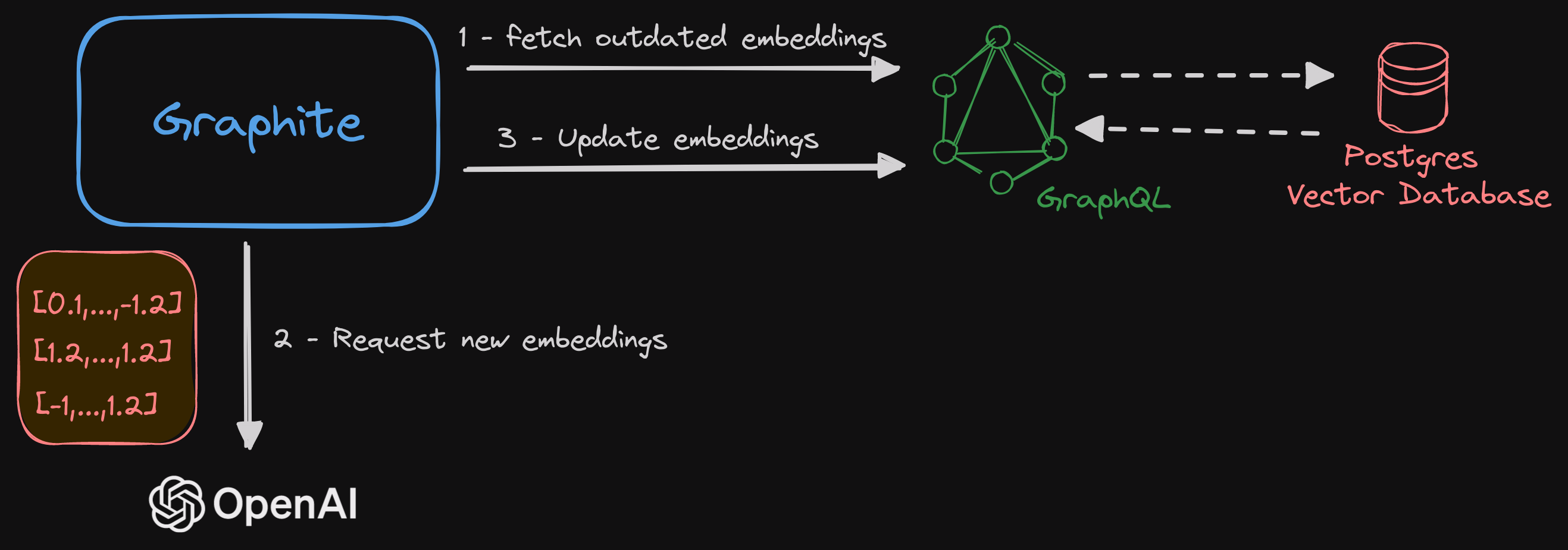 Graphite in action
Graphite in action
Semantic Search
Imagine effortlessly querying your data using natural language. Auto-Embeddings turns this a reality by integrating with your GraphQL API and offering a seamless and user-friendly experience.
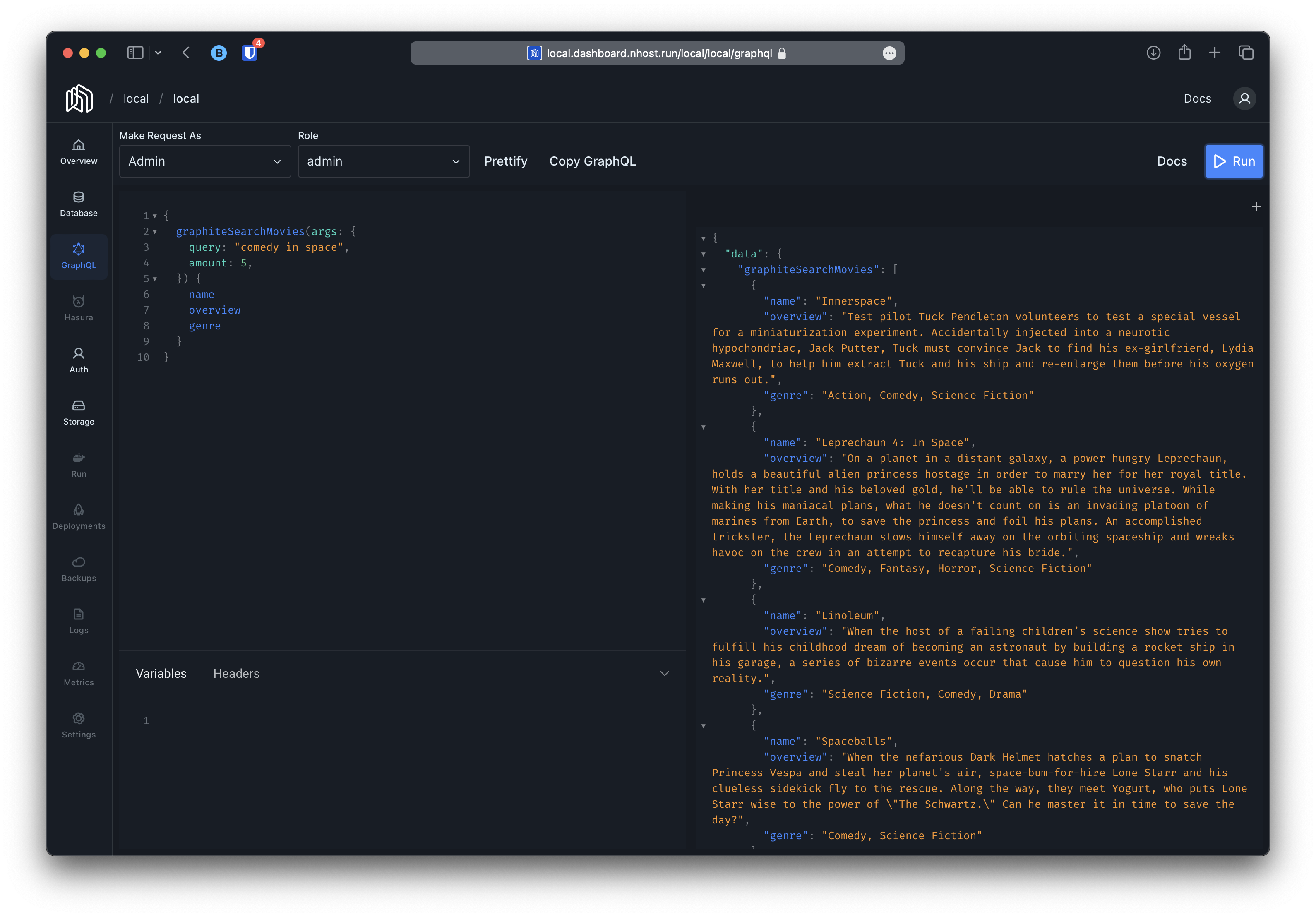 Movies on Space Comedy
Movies on Space Comedy
Once the movies Auto-Embedding is configured, the following queries are made available:
- graphiteSearchMovies
- graphiteSearchMoviesAggregate
- graphiteSimilarMovies
- graphiteSimilarMoviesAggregate
These queries will work similar to the standard movies and moviesAggregate queries provided by Hasura and will respect permissions the same way.
Pretty cool, right?
What's Next?
Although you can use pgvector already today, Auto-Embeddings will only be released on Friday, the 22nd, when we release graphite, our new AI service.
Wrap up
Vector Databases and Embeddings are a cornerstone of the AI revolution and we're excited to be part of it in any way we can.
This week marks the beginning of our AI journey to offer our users the best tooling to build great AI products and companies. Stay tuned!
Share this post